
Tech Talk: Hoe je voorspellende analyses kunt gebruiken voor cross-selling campagnes
In een verzadigde B2B-sector is cross-selling een interessante aanpak om inkomsten te verhogen tegen lagere kosten. Als een klant uw producten al heeft gekocht, is de verkoop van een ander product aan deze klant over het algemeen goedkoper dan het overtuigen van een nieuwe koper.
De meeste bedrijven vertrouwen op interne marketingexpertise om te beslissen met wie ze contact moeten opnemen in een cross-selling campagne. Een andere aanpak is om machine learning-methoden te gebruiken om beslissingen te nemen op basis van gegevens om te bepalen met welke klant contact moet worden opgenomen en welk product moet worden aangeboden.
In dit artikel richten we ons op het construeren van een machine-learningmodel voor cross-selling. Dit model zal voorspellen of een klant binnen een bepaalde tijdshorizon een ander product van het bedrijf zal kopen. Het doel is om de kenmerken van klanten die dit product kopen te identificeren en het vervolgens aan te bevelen aan soortgelijke klanten.
Gegevens begrijpen en transformeren voor modellering
Eerst halen we bruikbare gegevens uit de bronsystemen. Daarna transformeren we ze en maken ze beschikbaar voor modellering. Deze stappen worden Extract-Transform-Load (ETL) genoemd, waarover we eerder hebben geschreven.
Wat classificeren we precies? Een precies doel bepalen
Parallel aan de ETL moeten we de definitie van het doel verduidelijken met de marketingafdeling. Het doel is wat we gaan voorspellen. In ons geval hebben we het doel gedefinieerd als de productaankoop van de klant in de paar maanden na een bepaalde datum. In deze toekomstige periode, waarin we kijken of de klant koopt, noemen we het voorspellingsvenster.
Op welke informatie vertrouwen we? Praten met belanghebbenden
We analyseren het gedrag van klanten gedurende een bepaalde periode in het verleden om hun toekomstige gedrag te bepalen. We noemen deze periode in het verleden het observatievenster. Als we bijvoorbeeld weten dat een klant 5 jaar geleden 1000 euro heeft uitgegeven, is dat misschien niet relevant voor ons huidige probleem. Dezelfde klant die twee maanden geleden 500 euro uitgaf aan een ander product is waarschijnlijk geschikter.

Kunnen we voorspellen of klanten een product in de komende 6 maanden zullen kopen op basis van hun gedrag in de afgelopen 12 maanden?
We maken indicatoren die het koopgedrag van de klant beschrijven. We kunnen bijvoorbeeld het koopgedrag bestuderen op basis van het observatievenster. Zo berekenen we het uitgegeven bedrag per product, het aantal interacties met het verkoopteam, het aantal uitwisselingen met de dienst na verkoop, het aantal geopende commerciële e-mails, enz. Om deze indicatoren te berekenen, snijden we de relevante gegevens uit het bronsysteem en aggregeren we ze op verschillende manieren door ze op te tellen, het gemiddelde te nemen of verhoudingen te nemen. We noemen dit gedeelte meestal feature engineering.
Categorische variabelen coderen
Omdat we het classificatiemodel moeten trainen met numerieke gegevens, coderen we categorische gegevens, d.w.z. omgezet in numerieke waarden die door het model geïnterpreteerd kunnen worden. De meest bekende coderingsmethode is het creëren van één binaire variabele per categorie. We noemen dit one-hot codering. Deze methode is eenvoudig te implementeren en werkt meestal goed. Wanneer de te coderen variabele echter een grote kardinaliteit heeft, zal het creëren van een binaire variabele per categorie de dimensionaliteit van de dataset aanzienlijk verhogen. Dit kan ertoe leiden dat er niet genoeg trainingswaarnemingen zijn om het doel te voorspellen. Als een categorische variabele bijvoorbeeld 250 unieke waarden heeft, zal het coderen van deze variabele 250 binaire variabelen creëren.
Om deze variabelen met een grote kardinaliteit te coderen, is de doelcodering de oplossing. Voor elke categorie berekenen we de waarschijnlijkheid van het doel. Vervolgens vervangen we de categorie door de waarschijnlijkheid. We krijgen dan een enkele kolom met waarschijnlijkheden. Deze methode werkt goed voor variabelen zoals postcodes of NACE-codes.
Onevenwichtige klassen
Voor sommige producten waren er maar heel weinig klanten die ze gebruikten. In onze trainingsgegevens waren de twee klassen dan volledig uit balans - 5% van de populatie behoorde tot de klasse die het product snel zou kopen en de andere 95% niet. Deze verhoudingen zijn problematisch omdat de modellen zonder onderscheid alle waarnemingen in de meerderheidsklasse kunnen indelen. We nemen dan onze toevlucht tot oversampling- of subsamplingtechnieken om de balans tussen de klassen te herstellen, van 5%-95% naar 20%-70%.
Met andere woorden, we creëren kunstmatig nieuwe waarnemingen van de minderheidsklasse (oversampling) of verwijderen waarnemingen van de meerderheidsklasse. Over het algemeen voeren we beide procedures parallel uit om een evenwicht te bereiken. In het geval van deze studie hebben we een combinatie van oversampling met SMOTE en willekeurige subsampling uitgevoerd.
Modelprestaties meten in een marketingcontext
Zodra je voorspellingsmodellen hebt getraind, wil je evalueren hoe nuttig ze zijn. Je wilt ook een prestatiemeting hebben die iets betekent voor degenen die het zullen gebruiken, bijvoorbeeld het marketingteam. In deze context zijn kwaliteitsmetrieken meestal de lift op een bepaald punt of de cumulatieve (lift)winst bij een bepaalde drempel. Het voordeel van deze statistieken is dat ze direct interpreteerbaar zijn.
Deze statistieken vergelijken de prestaties van het model met een willekeurige selectie en beantwoorden de vraag "hoeveel beter is mijn model dan toeval? Stel dat we een cross-selling campagne willen lanceren en we willen een lijst met klanten om contact mee op te nemen.
Er zijn verschillende manieren om deze lijst samen te stellen. We kunnen vertrouwen op toeval, op de expertise van ons team, op een voorspellend model. Voor elke methode vragen we om de lijst te sorteren van de klanten die meer kans hebben om te kopen tot de klanten die minder kans hebben. Als we besluiten om alleen contact op te nemen met de eerste 10% van de lijst, krijgen we klanten waar het marketingteam of het voorspellende model het meeste vertrouwen in heeft. In het geval van het voorspellende model zal het model dat vertalen in hogere voorspellingsscores.
Een voorbeeld van cross-selling modelprestaties
Als 20% van onze klanten geïnteresseerd is in het kopen van een product, willen we ze zo snel mogelijk vinden zonder 100% van onze database te hoeven benaderen. Dat is precies waar de cumulatieve lift interessant is. Het geeft ons het percentage klanten dat we moeten benaderen om een bepaald percentage kopers te vinden.
Als we de grafiek hieronder nemen, hebben we op de x-as het percentage klanten dat door de campagne wordt bereikt. Het is duidelijk dat we eerst contact opnemen met klanten waarvan we meer vertrouwen hebben dat ze zullen kopen, klanten met een hogere voorspellingsscore. Op de y-as staat het percentage daadwerkelijke kopers met wie contact is opgenomen. Er zijn verschillende lijnen in de grafiek, een voor de methode die is gebruikt om de lijst te maken.

De cumulatieve lift voor een cross-selling probleem waarbij willekeurige selectie, expertise en voorspellend model worden vergeleken
Bij een willekeurige selectie van klanten worden kopers lineair gevonden, wat betekent dat als je contact opneemt met 20% van de klanten, je 20% van de kopers hebt gevonden. Dit is de basisprestatie die we willen overtreffen. Als we vertrouwen op een lijst van marketingexperts (turkooizen lijn), zullen we door contact op te nemen met de eerste 20% van de klanten ongeveer 40% van alle kopers vinden, twee keer meer dan bij een willekeurige selectie. Als we contact opnemen met de 20% klanten die worden aanbevolen door het voorspellende model (roze/rode lijn), vinden we 60% van alle kopers.
Dit is een handige manier om de prestaties van het model te beschrijven en in perspectief te plaatsen.
Voorspellende scores gebruiken om uw commerciële strategie te sturen
We kunnen dezelfde grafieken gebruiken om de contactstrategie af te leiden. De eerste klanten met een hogere voorspellende score konden we al overtuigen. Het is dus misschien niet nodig om geld uit te geven om contact met hen op te nemen, omdat ze het product toch wel kopen. Aan de andere kant van het spectrum zijn klanten in de laatste 10% meestal niet geïnteresseerd in het product. Contact opnemen met deze klanten kan dan leiden tot geldverspilling.
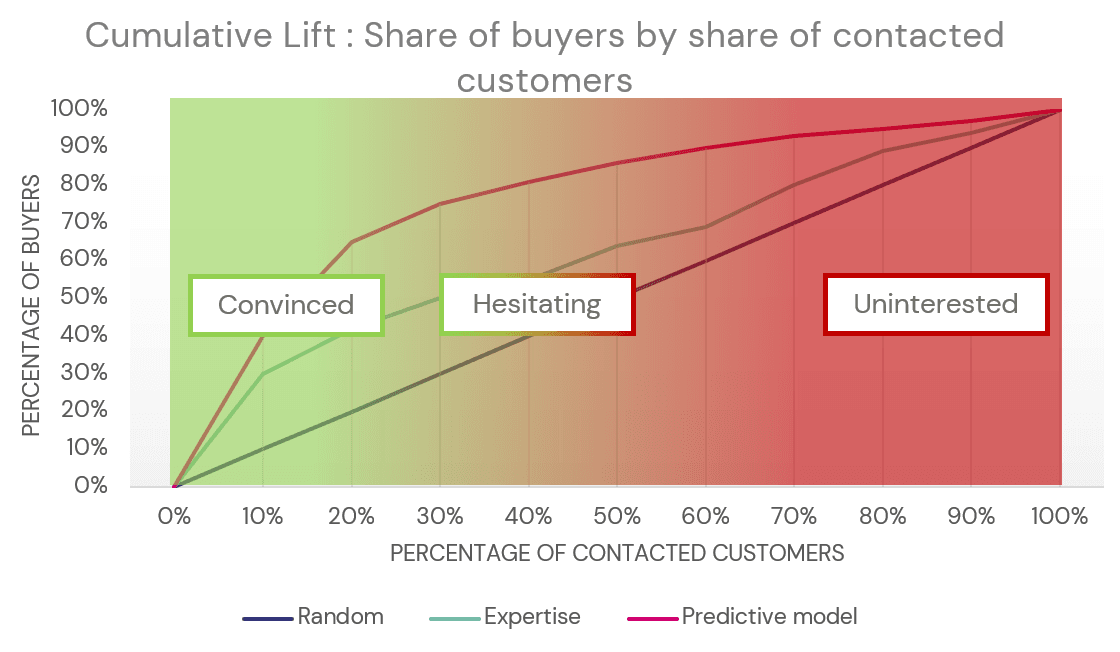
Rente afleiden voor het product door kwantiel
Hier kan de cumulatieve liftcurve de commerciële strategie bepalen. De bovenstaande grafiek wijst de verschillende kwantielen van klanten toe aan segmenten van degenen die al overtuigd zijn (hoge voorspellende scores), de aarzelende klanten (gemiddelde tot hoge voorspellende scores) en de ongeïnteresseerde klanten (lage voorspellende scores).
Uit deze segmenten kunnen we een strategie afleiden:
Ofwel het beveiligen van de overtuigden
Of aarzelende klanten veranderen in overtuigde klanten
De belangrijkste punten
In deze Tech Talk hebben we verschillende tips besproken om je te helpen bij het maken van een voorspellend model voor cross-selling en bij het efficiënt opbouwen van een commerciële strategie rond de output van je model. We hebben de volgende punten behandeld:
Het belang van het nauwkeurig definiëren van de doelstelling met het marketingteam,
Je trainingsgegevens opbouwen op basis van een observatievenster,
Zorgvuldig coderen van categorische variabelen,
Pas je trainingsgegevens aan voor onevenwichtige classificatie,
De cumulatieve lift gebruiken om de prestaties van je model te verklaren,
De cumulatieve lift gebruiken om de commerciële strategie af te leiden.