
Tech Talk: Is ETL in de cloud mogelijk zonder codering (deel 1)?
Afbeeldingen: https://www.agilytic.be/blog/tech-talk-etl-cloud-coding-part-1
Er is een tendens om alle dataoplossingen van on-premise naar de cloud te verplaatsen. Een in het oog springend argument kan de mogelijkheid zijn om de Total Cost of Ownership te verlagen. In deze 3-delige serie Tech Talks over ETL richten we ons op de mogelijkheden van de datatools van twee toonaangevende cloudspelers - Amazon Web Services (AWS) en Azure.
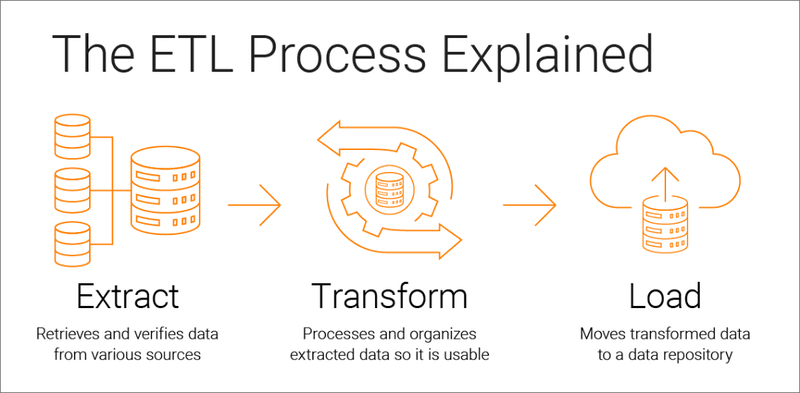
De fundamentele vraag: wat is ETL?
ETL vertegenwoordigt een typisch gegevensverplaatsingspatroon en staat voor Extract (uit een bron), Transform (de geëxtraheerde gegevens) en Load (de getransformeerde gegevens, meestal in een database, CSV, excel sheets of een data lake). Meestal sla je de geëxtraheerde gegevens ook op in cloud-opslag (S3 of blobs). De naam van dit proces zou dus waarschijnlijk ELT moeten zijn, of zelfs ELTL, omdat je de gegevens minstens twee keer laadt (of opslaat als je dat wilt).
ETL en codering in de cloud
Als je hier bent voor een snel antwoord op de vraag in de titel: Nee, ETL in de cloud bestaat niet zonder codering, buiten een paar eenvoudige scenario's die je gewoonlijk zou negeren.
Laat me dit toelichten. Bij ETL extraheer je niet twee tabellen uit één bron, voeg je ze samen en laad je de resulterende tabel in de database van je voorkeursleverancier. In plaats daarvan heb je te maken met tientallen of honderden tabellen uit verschillende bronnen. Vervolgens moet je complexe berekende velden/kolommen maken. Tot slot moet je de resultaten laden in verschillende modi zoals overschrijven, toevoegen, enz. Dat betekent dat er (bijna) altijd meer combinaties van bewerkingen zullen zijn dan die welke door de cloudleveranciers zijn voorzien en out-of-the-box voor u beschikbaar zijn.
Scenario's waarmee je te maken kunt krijgen: code of geen code?
Aangezien we drie fasen van het proces hebben, zijn er drie mogelijke bronnen van beperkingen en verschillende vragen om te beantwoorden:
Uittreksel. Is er een koppeling met deze gegevensbron? Kunnen we in bulk extraheren? Niet alleen tabellen scannen, maar ook views en gematerialiseerde views? Opslaan in parket?
Transformeren. Wat voor transformaties en aggregaties zijn er nodig? Kunnen we de gegevens gemakkelijk debuggen en vooraf bekijken in de ontwikkelingsfase?
Laden. Is er een verbinding met de gewenste gegevensverzamelaar? Welke formaten worden geaccepteerd? Kunnen we bulksgewijs laden? Kunnen we de wijze van laden kiezen?
Als het antwoord op een van deze vragen nee is, zul je het proces moeten aanpassen door code te schrijven. Om te beginnen, als je kijkt naar de populaire cloud tools zoals Azure Data Factory en AWS Glue, zul je een aantal basistemplates vinden voor eenvoudige scenario's. Met andere woorden, er worden wat UI tools gegeven, maar coderen is waarschijnlijk nog steeds 80% van elk ETL project. Met andere woorden, er worden wat UI tools gegeven, maar coderen is waarschijnlijk nog steeds 80% van elk ETL project. De populairste ETL programmeertalen zijn Python, Scala en SQL.
ETL Tech Talks volgende
In deel 2 en 3 beschrijven we twee cases waarin we Azure Data Factory en AWS Glue gebruikten om klanten te helpen bij het opzetten van hun ETL flows en data warehouses.