
Tech Discussie: Efficiënte wervingssuggesties met een aanbevelingstool
Laten we ons een banenmarkt voorstellen die zijn concurrentiepositie op de markt wil verbeteren.
Het doel is om gebruikers items aan te bieden die overeenkomen met hun individuele voorkeuren. De oplossing moet zo gebouwd zijn dat het mogelijk is om de items voor te stellen die de gebruikers het meest interesseren. Het moet echter ook mogelijk zijn om voor een item verschillende gebruikers te vinden die mogelijk geïnteresseerd zijn in dit item.
Dit kan worden bereikt door een aanbevelingssysteem te bouwen dat ze in hun platform kunnen integreren. In dit Tech Talk-artikel wordt uitgelegd wat aanbevelingssystemen zijn, hoe bedrijven er baat bij hebben en welke verschillende benaderingen je kunt kiezen bij het implementeren van een aanbevelingssysteem.
Wat zijn aanbevelingssystemen?
Aanbevelingensystemen zijn modellen voor machinaal leren die geïntegreerd zijn in platformen om gebruikers aanbevelingen te doen op basis van AI.
Aanbevelingssystemen zijn een veelbesproken onderwerp in de datawetenschap. Veel grote bedrijven zoals Netflix, Spotify en Amazon maken er een kernonderdeel van hun product van. In een tijdperk waarin AI-gestuurde aanbevelingen gemeengoed worden, is het belangrijk om te weten hoe je bedrijf er baat bij kan hebben en hoe je ze opbouwt.
Recommender-systemen kunnen op veel verschillende platforms en in veel verschillende branches worden geïmplementeerd. De voordelen voor een bedrijf kunnen verschillen, afhankelijk van hoe ze worden gebruikt en wat de doelen zijn. Hier zijn een paar manieren waarop ze een bedrijf van voordeel kunnen zijn:
Relevante inhoud leveren aan gebruikers/klanten - dit verhoogt de tijd die mensen op je website doorbrengen.
Converteer shoppers naar klanten omdat de kans groter is dat ze een product aanbevolen krijgen dat ze nodig hebben.
Meer inkomsten door klanten die meer producten kopen.
Klanten behouden - klanten die tevreden zijn met de producten die hen worden aanbevolen, zullen eerder terugkeren voor toekomstige aankopen.
We zullen de drie populairste aanbevelingssystemen bespreken om je een idee te geven van wat ze zijn en waar hun mogelijke tekortkomingen liggen, zodat je beter kunt beslissen bij welk systeem jouw bedrijf gebaat is. Deze zijn:
Filteren op inhoud
Collaboratief filteren
Hybride aanbevelingssystemen
Filteren op inhoud
Het doel van contentgebaseerde aanbevelingssystemen is om aanbevelingen te doen tussen een item en een gebruiker op basis van gelijkenis. De items die de meeste overlappende kenmerken hebben met de voorkeuren en/of eigenschappen van de gebruiker worden aanbevolen aan die gebruiker.
Deze methode houdt geen rekening met informatie over de voorkeuren van andere gebruikers. Het kan echter wel directe en indirecte informatie over de items en de gebruikers opnemen om hun gelijkenis beter te bepalen.
Een essentieel onderdeel van een contentgebaseerd aanbevelingssysteem is de informatie die we hebben over de interesses van de gebruiker - de gebruiker staat centraal. Zonder deze informatie zou het model geen goede aanbevelingen kunnen doen.
Normaal gesproken moeten gebruikers een profiel invullen wanneer ze zich voor het eerst aanmelden bij het platform, waar ze een aantal van hun interesses kunnen opgeven. Spotify vraagt nieuwe gebruikers bijvoorbeeld om hun favoriete artiesten en muziekgenres op te geven, zodat dit kan worden gebruikt om aanbevelingen te doen over soortgelijke genres of artiesten.
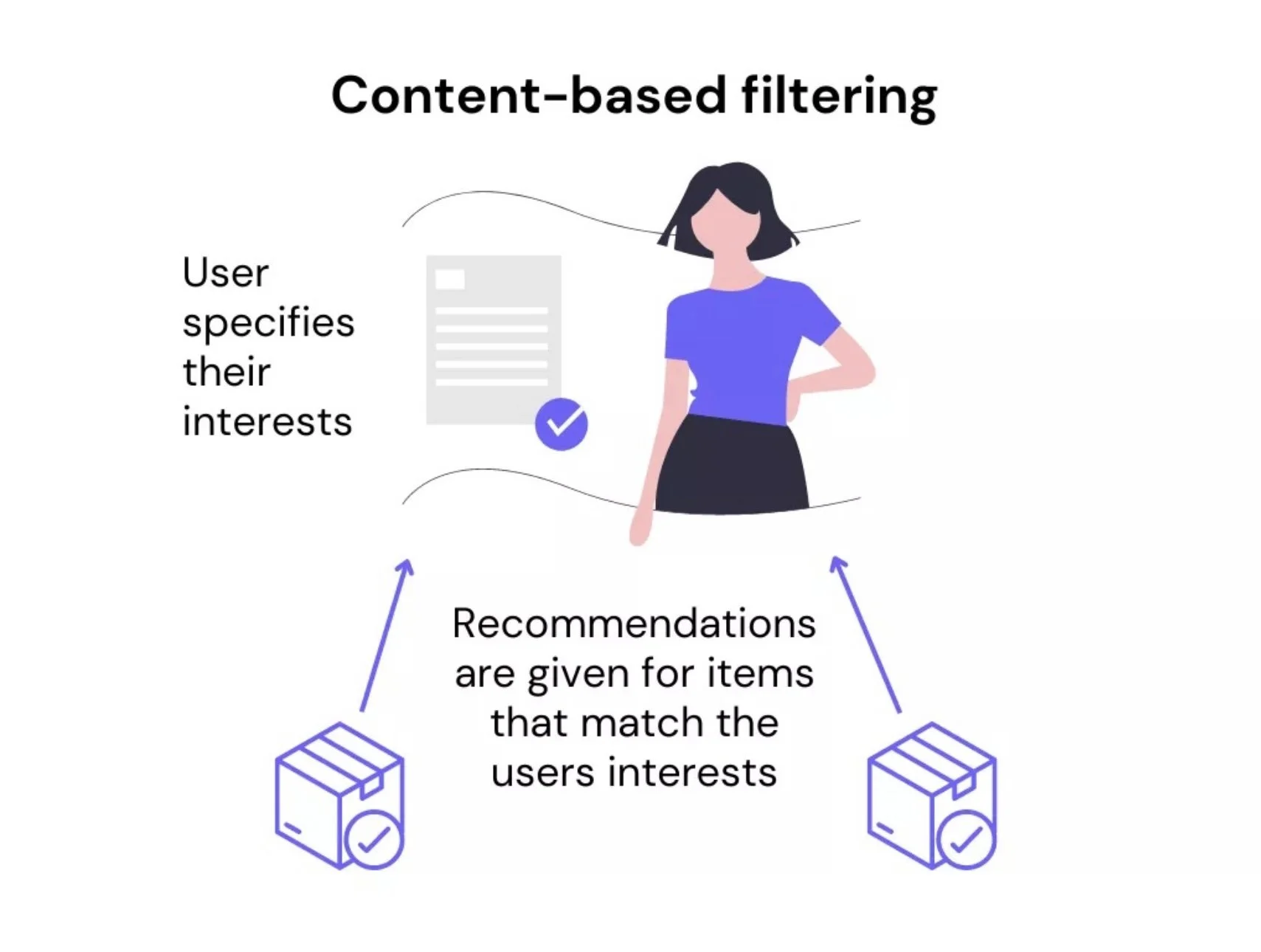
Filteren op inhoud kan helpen om het 'koude start probleem' op te lossen wanneer we niet voldoende historische gegevens hebben over de interacties van de gebruiker op de platformen. Aanbevelingen zijn echter specifiek voor de gebruiker en voor een zeer kleine subset van de items die kunnen worden aangeboden.
Er kunnen verschillende metrieken worden gebruikt om de gelijkenis tussen gebruikers en items te berekenen, zoals:
Euclidische afstand
Afstand Manhattan
Jaccard-afstand
Cosinusafstand/gelijkenis
Een van de populairste metrieken in deze lijst is de cosinusvergelijking. Deze methode berekent de gelijkenis tussen twee vectoren (de gebruiker en het item, bijvoorbeeld) met behulp van de cosinus van de hoek tussen hen. Dit betekent dat lagere hoeken tussen twee vectoren hogere cosinuswaarden hebben en dus veel op elkaar lijken.
Filtering op basis van samenwerking
Collaboratief filteren overwint enkele van de tekortkomingen van filteren op inhoud. Als we informatie hebben over eerdere interacties tussen de items en de gebruikers, kan dit gebruikt worden om een aanbevelingssysteem te bouwen dat een grotere verscheidenheid aan aanbevelingen biedt.
Als gebruiker A bijvoorbeeld een product koopt en gebruiker A lijkt op gebruiker B, dan zal dat product aan gebruiker B worden aanbevolen.

Gelijksoortige gebruikers worden gegroepeerd en het model houdt rekening met hun interacties met de items om aanbevelingen te doen aan andere gebruikers. Gebruikers kunnen een item expliciet een cijfer geven om aan te geven dat ze het wel of niet leuk vonden, of het systeem kan deze informatie afleiden op basis van alleen de interactie van de gebruiker met het item - als ze er bijvoorbeeld op klikken of het aan hun winkelwagentje toevoegen.
Een belangrijk nadeel van deze aanpak is echter dat er informatie over deze eerdere interacties nodig is, en dat is behoorlijk veel. Met andere woorden, het vereist een 'warme start'. Dit soort gegevens is niet altijd beschikbaar, vooral niet voor jongere platforms die geen grote gebruikersbasis of veel eerdere interacties hebben. Bovendien, als er nieuwe items worden toegevoegd aan het platform, zullen ze niet worden aanbevolen door het systeem totdat gebruikers er interactie mee hebben of ze beoordelen.
Er zijn twee methoden om modellen voor collaboratief filteren te bouwen: geheugengebaseerd en modelgebaseerd.
Op geheugen gebaseerde methoden berekenen de gelijkenis metric en doen dan aanbevelingen op basis van een algoritme zoals k-nearest neighbors.
Modelgebaseerde methoden gebruiken algoritmen voor dimensionaliteitsreductie om de matrix van gebruikersitems te comprimeren. Deze methode is vooral nuttig als de matrix schaars is - met andere woorden, gebruikers geven slechts aan een klein aantal items een beoordeling, zodat de meeste items in deze matrix leeg zouden zijn. Een veelgebruikte aanpak is het gebruik van het SVD-algoritme (singular value decomposition).
Hybride aanbevelingssystemen
Deze benadering combineert inhoudgebaseerd en collaboratief filteren in één aanbevelingssysteem. Op deze manier kunnen we het beste van beide werelden combineren en betere aanbevelingen krijgen door de tekortkomingen van elke benadering te overwinnen.
We kunnen een hybride model bouwen door inhoudelijke en collaboratieve systemen apart te creëren. Vervolgens kunnen we elk van hun scores combineren met behulp van een lineaire combinatie met gewichten die we kunnen specificeren.
Als er bijvoorbeeld niet genoeg gegevens zijn over de eerdere interacties van de gebruikers, kunnen we meer gewicht geven aan het op inhoud gebaseerde systeem. Zodra er in de toekomst meer gegevens beschikbaar zijn, kunnen we deze gewichten aanpassen.
Slotopmerkingen
Dit artikel introduceerde de soorten aanbevelingssystemen die de laatste jaren zo populair zijn geworden. Hoewel contentgebaseerde en collaboratieve filtering enkele nadelen hebben, kunnen ze worden opgenomen in een hybride systeem dat een krachtige aanpak biedt voor het doen van AI-aanbevelingen in je platform.
Er zijn twee laatste punten waar je rekening mee moet houden bij het bouwen van deze systemen:
Aanbevelingssystemen moeten regelmatig opnieuw worden getraind om relevant te blijven. Hoe vaak je dit doet hangt af van de groei van je platform en hoeveel nieuwe gegevens er binnenkomen.
De snelheid en prestaties van het algoritme zijn erg belangrijk wanneer je het in je platform integreert. Het optimaliseren van de code en de infrastructuur die voor dit systeem wordt gebruikt, is een cruciale stap waarmee voor en tijdens het project rekening moet worden gehouden.
Om meer te leren over aanbevelingssystemen heeft Google een gratis cursus die het onderwerp heel goed behandelt. Bekijk daarnaast de RecSys 2022 conferentie voor het laatste onderzoek en nieuwe manieren om aanbevelingssystemen te bouwen (voor een samenvatting van de conferentie schreef Eugene Yan een uitstekende samenvatting van enkele van de gepresenteerde papers).