
Tech Talk: Documentclassificatie en -voorspelling met behulp van een geïntegreerde toepassing (deel 2)
Dit artikel is een vervolg op een tweedelige serie. Voor nu bespreken we onze workflow voor ons documentclassificatieproject. Ten eerste verschijnt de startpagina van de app automatisch wanneer de gebruiker het bestand main.py uitvoert.
Zoals geïllustreerd in figuur 1, presenteren we twee opties. Ofwel kan de gebruiker het hele proces van het trainen van modellen uitvoeren om nieuwe aankomende documenten te voorspellen. Ofwel kan de gebruiker alleen documentvoorspelling gebruiken (gebaseerd op de specificatie van een eerder getraind model).
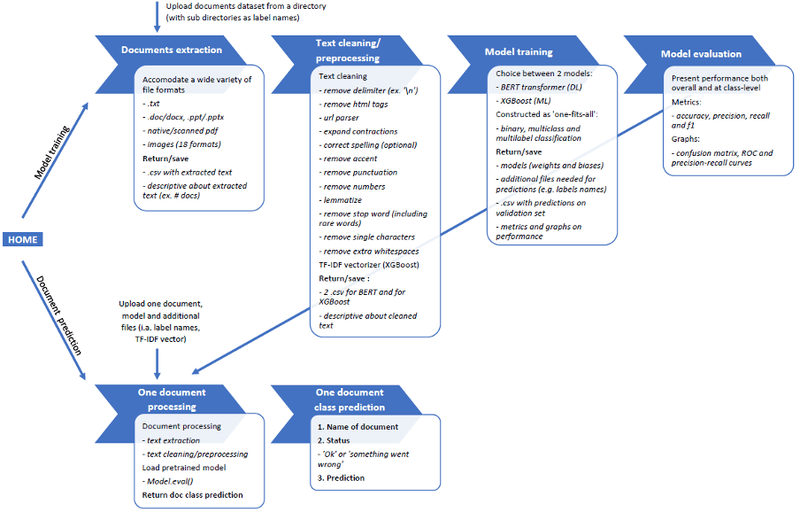
Figuur 1. De algemene workflow van de toepassing voor het classificeren en voorspellen van documenten
Python-programmering voor documentclassificatie
1. RESTful Flask API
We hebben twee API's gebouwd voor dit project, die gelijktijdig en voor verschillende doeleinden worden uitgevoerd.
De hoofd-API fungeert als een centraal raamwerk. Het coördineert het hele proces en de workflow en zorgt voor een soepele communicatie tussen de gebruikersinterface en de python objecten.
De secundaire API bevindt zich in het bestand main.py. Deze haalt de variabelen op die naar het systeem worden gestuurd wanneer asynchrone verzoeken worden uitgevoerd tijdens het navigeren door de app (JavaScript). Anders zouden we deze informatie niet kunnen ophalen.
2. Python-objecten
In totaal telt het project ongeveer tien python klasse objecten, waarvan we hier de belangrijkste presenteren.
Het klasseobject 'Extractor' van dit bestand kan een groot aantal bestandsformaten verwerken. Dit omvat zowel native documentbestanden als gescande document- of afbeeldingsformaten. De ondersteunde bestandsformaten zijn de volgende :
documentbestandsindelingen: .txt, .pdf, .doc/.docx, .ppt/.pptx
bestandsindeling afbeeldingen/gescande documenten: gescande pdf's, .bmp, .dib, .jpeg, .jpg, .jpe, .jp2, .png, .pbm, .pgm, .ppm, .pxm, .pnm, .pfm, .sr, .ras, .exr, .hdr, .pi
De documentextractor vertrouwt onder andere op de volgende bibliotheken: win32com, docx, pptx, pytesseract (OCR), pdfminer, pdf2image;
Het klasseobject 'TextCleaner' van dit bestand gebruikt de volgende NLP-tekstopschoningsmethoden: scheidingsteken verwijderen (bijvoorbeeld '\n'), HTML-tags verwijderen, URL parsen (alleen de domeinnaam behouden, zoals bijvoorbeeld 'cosmetic' voor www.cosmetic.be), samentrekking uitbreiden, spelling corrigeren (optioneel), accent verwijderen, interpunctie verwijderen, getallen verwijderen, lemmatize, stopwoorden verwijderen, enkelvoudig karakter verwijderen en extra witruimte verwijderen.
De verwerking van de correcte spelling is optioneel, een gebruiker kan deze gebruiken of niet gebruiken. Bijvoorbeeld tijdens het navigeren door de app-interface, zie de volgende sectie. We raden aan deze optie alleen te gebruiken als de tekst van lage kwaliteit is. Hiermee bedoelen we inhoud van sociale media met hun 'jargon' taal en scans en/of afbeeldingen van lage kwaliteit waar de OCR fouten zou kunnen produceren. Voor tekst waarvan bekend is dat deze van goede kwaliteit is (bijv. wetenschappelijke artikelen of samenvattingen), is het beter om deze optie niet te gebruiken. We hebben gemerkt dat de spellingcorrigerende bibliotheek soms correcte woorden vervangt door andere, vergelijkbare woorden, bijvoorbeeld 'fysisch' in plaats van 'topologisch'.
De functie 'stopwoord verwijderen' is gebaseerd op een lijst met stopwoorden die tijdens het proces wordt samengesteld. Deze lijst is gedeeltelijk gebaseerd op de bestaande stopwoordenlijst die wordt geleverd door sommige NLP-bibliotheken (waaronder sklearn, spacy, gensim en nltk). Deze lijst is ook gebaseerd op het corpus zelf, omdat het alle woorden bevat die slechts in één document voorkomen. De reden voor het opnemen van 'zeldzame' woorden is dat ze geen onderscheid maken tussen klassen en als ruis kunnen worden beschouwd.
Naast het opschonen van de tekst produceert TextCleaner ook de TF-IDF vectorizer die nodig is om het XGBoost model uit te voeren.
De twee modellen die we eerder hebben besproken, worden gematerialiseerd door twee andere klasseobjecten die dezelfde structuur hebben:
Gesplitste trein-validatie
Modeltraining
Modelevaluatie op de validatieset (30% van de totale steekproef)
Tijdens de training moesten we zowel multiklasse als multilabel datasets kunnen gebruiken. Daarom kozen we voor een gestratificeerde train-validatie opsplitsing in plaats van de meer conventionele train-validatie opsplitsing.
Wanneer het model tijdens de training geconfronteerd wordt met een multilabel dataset, houdt het rekening met het aantal oorspronkelijke klassen en alle gepresenteerde klassencombinaties. Het aantal potentiële klassencombinaties is dus veel groter dan het oorspronkelijke aantal klassen. Sommige klassencombinaties kunnen zeer weinig of zelfs geen documenten bevatten.
Figuur 2 toont de waardetellingen van elke specifieke klassencombinatie (als multiklasse één heet gecodeerd) voor een gegeven dataset. Zoals eerder vermeld, kunnen we zien dat sommige klassecombinaties niet in de telling voorkomen (bijv. [1 0 1 1 1 1]) omdat ze geen document hebben, en dat sommige andere zeer weinig documenten hebben (bijv. klassecombinatie [0 0 1 1 0 1] heeft slechts één document).

Figuur 2. Waardetellingen van klassencombinaties voor een multilabel dataset
In een dergelijke context is het risico van een conventionele train-validatiesplitsing dat sommige klassencombinaties die het model nog niet eerder heeft gezien tijdens de training, worden gepresenteerd tijdens de evaluatie. In dat opzicht zorgt de gestratificeerde train-validatiesplitsing ervoor dat de verhouding tussen de train-validatiesplitsing (in ons geval 70% vs. 30%) op de een of andere manier wordt gerespecteerd binnen elke klassencombinatie en dat er geen ongeziene klassencombinatie wordt gepresenteerd tijdens de evaluatie van het model.
Het klasseobject 'Rapport' biedt een gedetailleerde en diepgaande analyse van het model, zowel globaal als op klassenniveau, met onder andere classificatierapporten, verwarringmatrices, ROC-curves en Precision-recall-curves. Figuur 3 toont enkele voorbeelden van outputs uit dit rapport.
Wanneer de gebruiker tevreden is met de prestaties van een model, kan het object 'Prediction' een binnenkomende ongelabelde documentklasse voorspellen. Voordat de code wordt uitgevoerd, roept dit object de objecten 'Extractor' en 'Cleaner' aan om de tekst van de documenten precies zo voor te bewerken als tijdens de training.

Figuur 3. Voorbeelden van outputs uit het prestatierapport


Navigatie door de gebruikersinterface van de app voor documentclassificatie
Voor het weergeven van de HTML-bestanden die zijn ontworpen voor de gebruikersinterface, vertrouwt het huidige project op een python-specifieke grafische gebruikersinterface (GUI) wrapper (het pywebview pakket) omdat het enkele specifieke functionaliteiten toestaat die nodig zijn voor het uitvoeren van de code en die niet toegestaan zouden zijn met meer algemeen gebruikte webgebaseerde GUI (bijv. Google Chrome). Tijdens het proces moest het systeem het volledige pad van sommige bestanden of mappen ophalen, bijvoorbeeld om de dataset van de documenten te behandelen. Hoewel dit perfect mogelijk is met pywebview, zou Chrome in soortgelijke gevallen het bestand uploaden en de bestandsnaam ophalen (zonder het pad).
We hebben de gebruikersinterface zelfverklarend en intuïtief ontworpen. Bovendien probeerden we de gebruiker controle te geven over elke stap van het proces en een goed overzicht te bieden van hoe de dingen verlopen (tussentijdse rapporten na elke stap en voor het starten van de volgende). De bedoeling was om de gebruiker een goed inzicht te geven in de gegevens, de gegevensverwerking en de kwaliteit van het model. Figuur 4 toont de startpagina van de gebruikersinterface van de app.

Afbeelding 4. Startpagina van de gebruikersinterface van de app
De webapp voor documentvoorspelling
Zoals eerder vermeld, heeft de web app alleen betrekking op de documentvoorspellingsworkflow (en niet op de modeltrainingworkflow). In die zin gebruikt het dezelfde pythoncode als het hele project (maar alleen de klassen en functies die worden gebruikt voor de voorspelling), maar er moeten enkele wijzigingen worden aangebracht met betrekking tot de gebruikersinterface en de implementatie.
Als de gebruiker een document uploadt, wordt de voorspelling automatisch verwerkt en wordt de gebruiker vervolgens doorgestuurd naar de pagina met het voorspellingsrapport:
De naam van het document
Status: 'ok' of 'ko' (wat betekent dat er iets fout is gegaan: het bestandsformaat wordt niet ondersteund, of het document is geopend in een ander systeem/software
Voorspelde klasse
Een ander nadeel ten opzichte van de lokale app is dat de HTML-bestanden uit pywebview moesten worden gehaald om ze in een webbrowser/GUI te kunnen renderen (zie afbeelding 5).

Afbeelding 5. Startpagina van de webapp
De webapp werd ingezet op Microsoft Azure om de goede werking ervan te testen. We gebruikten Docker om de ontwikkelomgeving te creëren. Voor het gebruik van Docker werden twee bestanden aangemaakt:
Met de 'Dockerfile' kunnen we een Docker image van het project maken met alle vereisten om het uit te voeren (inclusief alle python pakketten die door het systeem worden gebruikt).
Het bestand 'docker-compose.yml' geeft alle nodige instructies aan de hostingomgeving om de app te starten en te laten draaien.
Travis CI is een gehoste continue integratiedienst die wordt gebruikt om softwareprojecten te bouwen en te testen die worden gehost op GitHub. Als aanvulling op Docker gebruikten we Travis CI ook om een directe verbindingslijn te maken tussen de lokale repository (gekloond van de huidige repository) en de webapp die op Azure wordt ingezet. In het belang van dit project is het eenvoudiger om het systeem bij te werken met nieuw getrainde modellen.
Conclusie en mogelijke verdere ontwikkelingen voor documentclassificatie
Over het algemeen heeft het huidige project een punt bereikt waarop het goed presteert en zeer functioneel is (of het nu wordt gebruikt door onervaren gebruikers of door deskundige gebruikers). Zolang we de data op de juiste manier aan het systeem presenteren (de map met de datasetdocumenten met submappen als labelnamen), kan de app overweg met verschillende bestandsformaten en datasettypes (voor binaire, multiklasse of multi-label documentclassificatie).
In die zin biedt dit project zeer veelzijdige tools die we kunnen aanpassen aan verschillende business cases. Tot slot zijn zakelijke toepassingen van het type van het huidige project ook vrijwel oneindig. Om maar een paar voorbeelden te noemen:
De verzending van bedrijfsdocumenten automatiseren (naar de juiste persoon of de juiste afdeling);
E-mailverzending en -sortering automatiseren
Verbetering van de prestaties van zoekmachines voor document/tekstinhoud
Spam of frauduleuze/atypische documenten detecteren
Tekst uit medische dossiers behandelen om pathologieën en comorbiditeiten te detecteren (multilabel-achtige situatie). Hoewel een dergelijk systeem ook aanvullende medische gegevens van patiënten zou moeten integreren, zoals medische beelden en testresultaten.