
Ontketenen van causaal machinaal leren om besluitvorming te verbeteren
In de wereld van machine learning vormen nauwkeurige voorspellingen vaak de ruggengraat van de besluitvorming. Maar in een omgeving waar context en acties voortdurend veranderen, kan de robuustheid van voorspellingsmodellen na verloop van tijd in het gedrang komen.
Voor een uitgebreidere strategie is het raadzaam om het domein van Causal Machine Learning te verkennen. Deze geavanceerde benadering stelt ons in staat om oorzaak-en-gevolgrelaties te onthullen en nauwkeurige resultaten te bereiken om te anticiperen op de uitkomst van specifieke acties.
Causaal machinaal leren begrijpen
Traditioneel Machine Learning richt zich voornamelijk op het identificeren van correlaties en het doen van voorspellingen op basis van deze correlaties.
Causal Machine Learning gaat een stap verder door te streven naar het begrijpen van de oorzaak-en-gevolg verbanden tussen variabelen. Bij Causal ML is het doel niet alleen om de kenmerken te bepalen die bijdragen aan het voorspellen van een uitkomst, maar ook om de causale factoren te ontdekken die de uitkomst veroorzaken en hun impact nauwkeurig te kwantificeren.
-
Neem bijvoorbeeld de taak van het voorspellen van klantverloop. Stel dat we voor een telecomoperator werken waarvoor we een uitgebreide dataset creëren waarmee we voor elke klant nauwkeurig het verloop kunnen voorspellen.
Na het trainen van een ML-model en het uitvoeren van rigoureuze tests, werd het duidelijk dat de prijs van het abonnement naar voren kwam als de meest invloedrijke eigenschap. Na de presentatie van onze resultaten namen de zakelijke belanghebbenden de logische beslissing om een korting toe te kennen aan de klanten die als "risicovol" werden geïdentificeerd. Hierdoor konden ze de meeste klanten behouden.
Later, wanneer het model opnieuw wordt gevraagd om churn-niveaus te voorspellen, krijgt de klant een resultaat dat aangeeft dat er momenteel nul klanten risico lopen. Dit resultaat is zakelijk gezien niet erg zinvol.
Door een korting toe te kennen om klanten te behouden, verstoorde de operator de relatie tussen prijs en klantenverlies en gaf hij een dwingende reden voor zijn beslissing.
-
Het concept dat je in gedachten moet houden bij het ontwikkelen van een voorspellingsmodel is dat de eigenschap met de hoogste belangrijkheidsscore:
Misschien niet de beste eigenschap om op te reageren (wat als de beste eigenschap de leeftijd van de klant was?)
Misschien heeft het zelfs helemaal geen invloed op de uitkomst.
Deze laatste opmerking zou enige verbazing kunnen wekken. Het is echter bekend dat correlatiepatronen vals kunnen zijn.

Uitsluitend focussen op voorspellingen is acceptabel, maar het wordt problematisch wanneer er beslissingen worden genomen op basis van die voorspellingen, vooral wanneer die beslissingen direct van invloed kunnen zijn op de huidige toestand van de omgeving. Causal ML verlegt de aandacht van louter voorspellende modellen die afhankelijk zijn van correlaties naar modellen die de machinerie van oorzaak en gevolg kunnen aandrijven.

Bron: XKCD
Causaal Machine Leren
Dit is het perfecte moment om een precieze definitie te geven van Causal Machine Learning. Causal ML vertegenwoordigt een verschuiving in focus vanuit een modelleringsperspectief:
In plaats van voorspellingen te doen, proberen we de variabelen te identificeren die verantwoordelijk zijn voor de uitkomst.
Schat in hoe die uitkomst zou veranderen als we die variabelen zouden veranderen.
Of, op een meer formele manier: Een behandeling T veroorzaakt een uitkomst Y als en slechts als verandering van T leidt tot verandering van Y terwijl al het andere constant blijft.
Als we deze verandering vanuit zakelijk oogpunt bekijken, gaat de evaluatie in wezen over het beantwoorden van de vraag "wat als?". Wat als ik de prijs die ik de klant aanbied niet zou veranderen? Hoeveel klanten zouden dan overstappen? Dit is wat algemeen bekend staat als een counterfactual. Stel het je voor als een parallelle dimensie, waar alles onveranderd blijft behalve de manier waarop dingen worden afgehandeld.
Het simuleren van een parallel universum is ontegenzeggelijk een uitdaging, net als het voorspellen van het contrafeitelijke. We observeren dit universum nooit en er kunnen verschillende causale structuren zijn die passen bij je probleem. Dit betekent verschillende behandelingen om rekening mee te houden. Dus, hoe doe je het?
Causale ML toepassen
Causaal Machine Leren schittert wanneer het wordt gekoppeld aan een diepgaand zakelijk inzicht en een solide basis in logisch redeneren.
De eerste stap is modellering, waarbij we een causaal diagram construeren dat de behandeling, het resultaat en de mogelijke verstorende variabelen omvat. Dit is waar je de zakelijke belanghebbenden zoveel mogelijk bij wilt betrekken, omdat hun inzichten zeer waardevol zullen zijn. Voor het bovenstaande voorbeeld van churn zou de Direct Acyclic Graph er bijvoorbeeld zo uit kunnen zien:
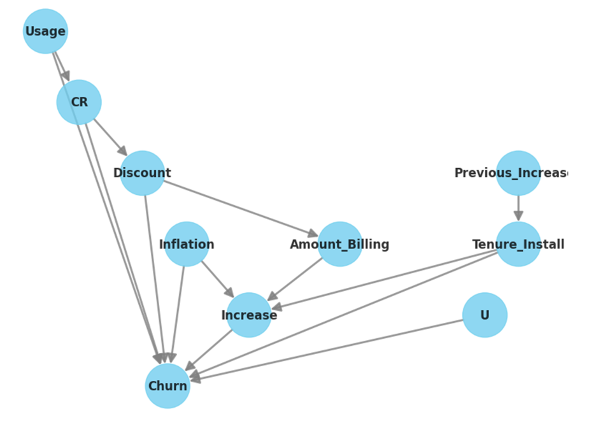
De volgende cruciale stap is identificatie, waarbij je zorgvuldig het algoritme kiest dat jouw specifieke scenario effectief zal aanpakken. Dit kan een aantal opties inhouden, zoals gerandomiseerde experimenten, grondige overweging van verstorende factoren of het uitvoeren van rigoureuze A/B-tests. Microsoft's Causal ML biedt een beslisboom om te helpen bij het kiezen van de juiste library voor jouw context.
Na de modellering en identificatie is de derde stap het uitvoeren van de schatting, waarbij het geselecteerde algoritme wordt toegepast op je dataset.
De beslissende stap is de weerlegging, waarbij de geldigheid van het model wordt getest. Dit kan in de vorm van een placebotest, waarbij de behandeling wordt vervangen door een willekeurige waarde om te zien of er enig effect is op de uitkomst.
De netelige kwestie van A/B-testen
Experimenten uitgevoerd door het team van Microsoft illustreren de overvloed aan toepassingen voor Causal Machine Learning. Ze omvatten scenario's zoals het bestuderen van annuleringen van hotelboekingen, het analyseren van de effectiviteit van loyaliteitsprogramma's voor klanten of zelfs het voorspellen van het verloop van klanten.
Op dit punt in het artikel zouden lezers kunnen overwegen: "We implementeren causaal machine leren al. Ik heb onlangs A/B-tests uitgevoerd."
Hoewel A/B-testen een belangrijk onderdeel is van Causal ML, moet het met grote zorg worden benaderd, vooral in een zakelijke context.
Het succes van A/B-testen is sterk afhankelijk van essentiële aannames, waaronder het uitvoeren van slechts één experiment per keer. Bovendien kun je met A/B-testen niet a priori onderscheid maken tussen je klanten.
Laten we een nieuw voorbeeld nemen. Stel je voor dat je twee sushisrestaurants hebt. Die restaurants zijn in elk opzicht vergelijkbaar. Grootte, eten, prijzen, klantensegmentatie...
Op een dag heb je genoeg van sushi's en verlang je naar een nieuw culinair avontuur. Op dat moment maak je de gewaagde keuze om een geheel nieuw en verleidelijk gerecht te introduceren.
Je wordt echter verscheurd tussen de salades en de pasta.
Je besluit een A/B-test uit te voeren en in restaurant 1 alleen salades te serveren en in restaurant 2 alleen pasta.
Na een maand lang de omzetgegevens te hebben geanalyseerd, wordt het overduidelijk dat pasta ongetwijfeld de meest winstgevende optie is! Onze beide restaurants zijn gespecialiseerd in het serveren van een grote verscheidenheid aan heerlijke pastagerechten. Deze optie voldoet misschien niet aan de verwachtingen van al je klanten.
Doel: Klanten die graag borden spaghetti verorberen, maar snel weggaan bij een restaurant dat alleen salades serveert.
Zeker weten: Wat je ook kookt, deze klanten zullen naar je restaurant komen.
Verloren zaken: Het maakt niet uit wat je op het menu aanbiedt, deze klanten zullen nooit in je restaurant dineren.
Sleepy Dogs: Als u stopt met het serveren van sushi, zullen deze klanten vertrekken.

In een perfecte wereld zou je je uitsluitend kunnen richten op je doelklanten.
Helaas kan niemand tegelijkertijd behandeld en onbehandeld zijn. Slechts één van deze potentiële uitkomsten kan ooit worden waargenomen. De niet-waargenomen uitkomst is een contrafeitelijke uitkomst. Gebrek aan causale inferentie kan leiden tot een onverwacht verlies van klanten, wat je verwachtingen zou kunnen overtreffen.
Waarom causaal machinaal leren belangrijk is
Causal Machine Learning biedt inzichten die niet kunnen worden afgeleid uit louter voorspellingen. Door zich bewust te zijn van oorzaak-en-gevolgrelaties kan een bedrijf beter geïnformeerde beslissingen nemen en daardoor robuuste strategieën creëren die relevant blijven ondanks de snel veranderende omgeving.
Hoewel het proces veeleisend lijkt, zijn de beloningen evenredig, variërend van Nobelprijzen voor onderzoekers tot praktische zakelijke voordelen. Als je het eenmaal onder de knie hebt, kan Causal Machine Learning een tijdperk inluiden van verbeterde besluitvorming op basis van gefundeerde inzichten.