
Tech Talk: Hoe documentfoutdetectie uit vergoedingsaanvragen automatiseren
Foutdetectie documenteren om fouten en handmatige processen te verminderen
Als je je klanten vraagt om een sjabloondocument in te vullen, kunnen er fouten zitten in de informatie die de klanten verstrekken. Dit betekent dat je handmatig moet controleren of er fouten zijn voordat je het document valideert. Deze manier van werken is een kostbaar proces waarvoor veel medewerkers nodig zijn om elk document te controleren.
Een verzekeringsmaatschappij nam contact met ons op omdat ze per jaar meer dan 100.000 rekeningen van hun klanten voor medische terugbetaling ontvingen. Het volgende project voor het opsporen van documentfouten bestond uit het classificeren van facturen in twee categorieën: 1) het document moet worden aangepast, of 2) dat is niet het geval. De invoergegevens hebben 117.000 rekeningen en 312 kenmerken. We kunnen het opsplitsen in de kenmerken:
Kenmerken markeren over de aanwezigheid van een bepaalde coderegel in de rekening
Bedragen die op de factuur worden weergegeven (terugbetalingsbedrag, aanvullend bedrag, totaalbedrag)
Type ziekenhuis, kamers en facturen
Metagegevens over de rekening (aantal vermeldingen en data)
De meeste fouten komen door het gebruik van de verkeerde code voor diensten die het ziekenhuis heeft ontvangen. Vervolgens komt het doordat de datum die op de rekening wordt gebruikt niet de juiste is, of doordat het bedrag dat wordt vermeld ook niet juist is.
De gegevens voorbewerken voor detectie van documentfouten
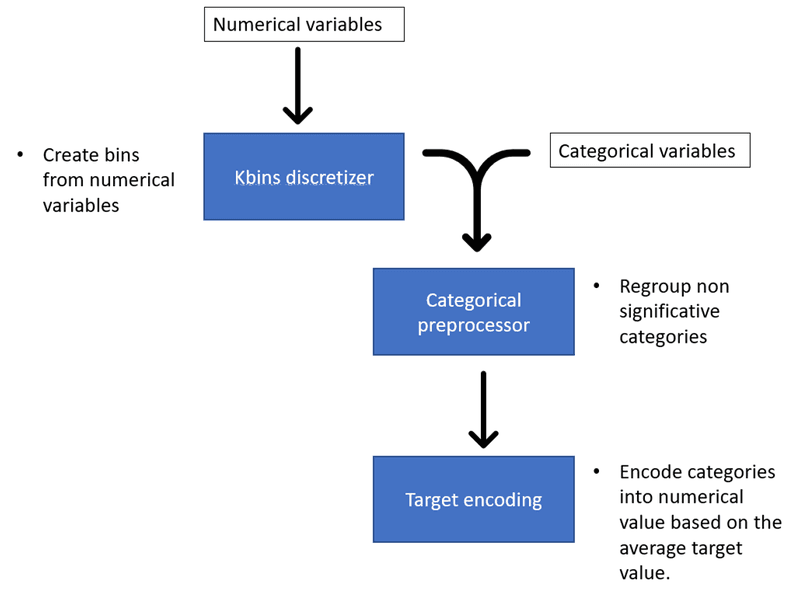
Voordat we de gegevens naar het model voor onze documentfoutdetectie sturen, is het beter om ze eerst voor te bewerken. We kunnen nieuwe variabelen creëren om betere prestaties te leveren, wat feature engineering wordt genoemd. We moeten continue variabelen categoriseren in bins. Vervolgens moeten we categorische variabelen omzetten in numerieke variabelen zodat het model ze kan verwerken.
Feature engineering voor detectie van documentfouten
Om dit te bereiken gebruiken we de cobra bibliotheek, die verschillende functies implementeert om de gegevens voor te bewerken. Cobra is handig omdat je verschillende preprocessingfuncties kunt toepassen en afstemmen met slechts een preprocessorobject.
Functie-engineering
We kunnen proberen het model te helpen nieuwe patronen in de gegevens te ontdekken door nieuwe variabelen te maken. De interactie tussen verschillende variabelen kan deze variabelen maken. We maken bijvoorbeeld de verhouding van het vergoedingsbedrag door het vergoedingsbedrag te delen door het totale bedrag.
We kunnen ook patronen vinden in gegevens door de tijd heen. Dus als je een datumvariabele hebt, kun je die gebruiken om een maand-, weekdag- en seizoensvariabele te maken. Het model zou verborgen cycli kunnen vinden die verschijnen tijdens maanden, weekdagen of seizoenen.
Kbins Discretizer
Kbins Discretizer zal continue gegevens opdelen in intervallen van een vooraf gedefinieerde grootte. Dit is interessant omdat het niet-lineariteit in het model kan introduceren. Je kunt een aantal bins instellen en de strategie die wordt gebruikt om de bins te maken. Er zijn drie strategieën in KBinsDiscretizer:
Uniform: De binbreedtes zijn constant in elke dimensie.
Kwantiel: Elke bin heeft hetzelfde aantal samples.
Kmeans: De discretisatie is gebaseerd op de centroïden van een KMeans-clusteringprocedure.[1]
Preprocessor voor categorische gegevens
De categoriale data preprocessor geïmplementeerd door Cobra zal de categorieën van categorische variabelen hergroeperen gebaseerd op significantie met de doelvariabele. Een chi-kwadraattest bepaalt of een categorie significant verschilt van de rest van de categorieën voor het classificatiemodel, gegeven de doelvariabele.
We kunnen de p-waardedrempel instellen om te bepalen bij welke p-waarde de categorieën significant zijn of niet. Als de categorie niet significant is, wordt deze gehergroepeerd onder de categorie "Overige".
We kunnen ook de minimale grootte van een categorie instellen om deze als aparte categorie te behouden. De categorie wordt gehergroepeerd onder de categorie "Overige" als de categorie kleiner is dan deze minimale grootte.
Er is ook een optie om de ontbrekende waarden te vervangen door de extra categorie "Ontbreekt".
Met deze module kunnen we alleen relevante categorieën behouden en het aantal geïsoleerde gegevensmonsters in de dimensieruimte verminderen.
Doelcodering
Doelcodering (of gemiddelde codering) berekent de verhouding van positieve gebeurtenissen in de doelvariabele voor elk kenmerk. Het is een manier om categorische waarden om te zetten in numerieke waarden.

De doelcoderingsmethode voor het opsporen van documentfouten
Doelcodering heeft de voorkeur boven de traditionele one-hot codering omdat het geen extra kolommen toevoegt. One-hot codering zou veel dimensies toevoegen aan onze dimensionale ruimte die al uit 300 kenmerken bestaat. Een hoog-dimensionale ruimte heeft twee problemen:
Het verhoogt het geheugen- en rekengebruik.
Het verhoogt het vermogen van het model om de gegevens te overpassen.
Doelcodering maakt het dus mogelijk om het geheugen- en rekengebruik en de overfitting van het model te verminderen.
Doelcodering kan echter nog steeds leiden tot overfitting omdat het de verhoudingen berekent op basis van de trainingsvoorbeelden die we geven. De verhoudingen zijn misschien niet hetzelfde in het testvoorbeeld. In ons testvoorbeeld zou 'Kleine kamers' bijvoorbeeld een ratio van 0,75 in plaats van 0,5 kunnen hebben. We kunnen dit probleem verminderen door additieve afvlakking te gebruiken. Cobra kiest ervoor om dit te implementeren voor zijn doelcoderingsklasse. Bij het berekenen van de verhouding van positieve gebeurtenissen voor elke categorische waarde, voegt het de verhouding van positieve gebeurtenissen van de doelvariabele proportioneel toe aan een gewicht. Max Halford legt dit gedetailleerd uit in zijn artikel.
Model en resultaten voor detectie van documentfouten
Gebaseerd op de behoefte van de klant, is de geschikte metriek de Area Under the Curve (AUC).
We selecteren de kenmerken die de AUC aanzienlijk verhogen. Om te voorkomen dat er te veel dimensies zijn en om de kans op overfitting te verkleinen, hebben we alleen de kenmerken geselecteerd die de AUC met een aanzienlijke marge verhoogden. Met andere woorden, we hebben een voorwaartse selectie uitgevoerd.
Het beste model is de Gradient boosting tree. We gebruiken de XGBoost-bibliotheek, een geoptimaliseerde gedistribueerde gradient boosting-bibliotheek die is ontworpen om zeer efficiënt, flexibel en overdraagbaar te zijn. De bibliotheek implementeert vroegtijdig stoppen om overpassen van de trainingsgegevens te voorkomen. Het is ook mogelijk om andere parameters op te geven, zoals de maximale diepte van elke boom of de minimale som van instance gewichten die nodig zijn voor een child. Je kunt alle beschikbare parameters hier bekijken.
We behaalden een AUC van 86,3%.

ROC-curve als resultaat van het project voor detectie van documentfouten
Conclusies
We konden 47% van de facturen automatiseren met een foutpercentage van 3,06%. Dit betekent dat ongeveer 55.000 documenten niet handmatig hoefden te worden gecontroleerd, wat de klant talloze uren bespaart.
[1] https://scikitlearn.org/ stable/auto_examples/preprocessing/plot_discretization_strategies.html