
Tech Talk: Zoeken in een groot tekstveld met Elasticsearch-markering en Kibana (deel 2)
In deel 1 van deze artikelreeks hebben we opgeslagen velden gepresenteerd en hoe u de standaardconfiguratie in Elasticsearch kunt wijzigen. Volgens onze dataset heeft het wijzigen van de standaardconfiguratie de prestaties niet verbeterd. Hier bespreken we de Elasticsearch highlighting functie, de configuratie en de potentiële prestatieverbetering die we kunnen bereiken.
Het is vaak handig om te weten welk woord of token uit documenten overeenkomt met onze zoekopdracht. In Elasticsearch heet de functie om het token te markeren, je raadt het al, markeren. Deze functie kan in bepaalde gevallen CPU-intensief en tijdrovend zijn. Een van die gevallen is markeren vanuit een groot tekstveld. We zullen de verschillende markeermethoden bekijken zonder in te gaan op technische details. Daarna vergelijken we de prestaties van de methoden op basis van onze use-cases en dataset.
Ter herinnering: onze dataset bestaat uit JSON-documenten die metagegevens bevatten zoals "titel" en "auteur". Een extra veld bevat de geëxtraheerde tekst uit de PDF. Dit veld heeft een gemiddelde grootte van 200K karakters (200 KB).
Markeren met Elasticsearch
We moeten weten of we het markeerproces in Elasticsearch op onze dataset kunnen optimaliseren. Volgens de officiële documentatie kunnen we parameters instellen voor de manier waarop we onze zoekresultaten willen markeren. We zullen proberen onze highlightingprestaties te optimaliseren op basis van twee verschillende parameters:
1. Offsetstrategie: Postings: het voegt een offset-locatie toe voor elke term in de omgekeerde index. Op deze manier kan Elasticsearch de locatie van een specifieke term zonder analyse snel te weten komen.
Term vector met with_positions_offsets: Een extra datastructuur die geavanceerde functies biedt voor het scoren van resultaten. Volgens de officiële documentatie is dit het meest efficiënt voor een groot veld (> 1 mb). Het verbruikt waarschijnlijk ook veel meer schijfruimte.
Opmerking: de standaardconfiguratie van Elasticsearch is om documenten te indexeren zonder een offset te berekenen.
2. Markeerstift: Unified: met BM25 algoritme om resultaat te scoren. Dit is de standaard highlighter.
FVH (Fact vector highlighter): met tf-idf algoritme, het vereist het gebruik van een term vector met_positions_offsets.
Plain: Het herbouwt een complete kleine in-memory index tijdens de query voor elk document en veld.
Standaard bouwt Elasticsearch noch de postings noch de termvectoren. Dit betekent dat de markeerfunctie de Unified highlighter zonder offset-strategie gebruikt.
Als je een bepaalde markeerstift kiest, zullen sommige functies niet meer toegankelijk zijn. We raden je aan de officiële documentatie te lezen.
Prestatiemeting met Elasticsearch
We hebben besloten om de prestaties van verschillende markeerconfiguraties te meten. Deze metingen zijn bedoeld om een schatting te maken van de beste configuratie om te kiezen in een proof of concept. Deze metingen kunnen op de een of andere manier vertekend zijn. Onze testomgeving wordt namelijk niet continu belast, zoals bij een productieomgeving, maar is alleen bedoeld voor het schatten van de prestaties!
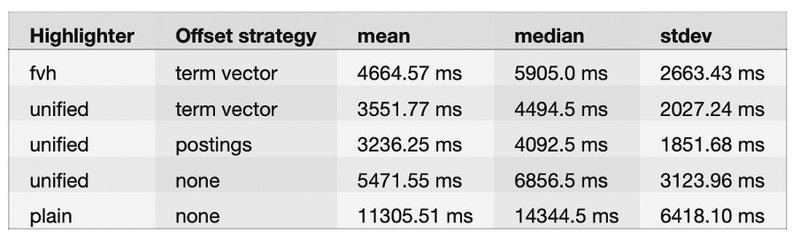
Onze test gebruikte de resultaateigenschap "duurde" als een representatieve hoeveelheid milliseconden die het duurde voordat de query terugkwam. We hebben 100 zoekopdrachten uitgevoerd met een grootte van 1000 documenten op drie verschillende indices, elk met een andere offset-strategie.
Het is geen verrassing dat de gewone markeerstift zonder offset strategie ondermaats presteert vanwege de technische implementatie. Volgens onze dataset lijkt de standaard unified highlighter met postings offset strategie het meest efficiënt. Bovendien lijkt deze beter te presteren op onze dataset dan FVH met de termvector offset strategie. Wij geloven dat termvector met FVH beter zou passen bij grotere tekstvelden zoals vermeld in de officiële documentatie (> 1 MB).

Term vector verbruikt duidelijk de meeste schijfruimte vanwege de extra gegevensstructuur. We kunnen zien dat de postings het schijfgebruik met ongeveer 20% verhogen, wat naar onze mening nog steeds betaalbaar is vanuit een zakelijk perspectief.
Als we rekening houden met de prestaties en het schijfgebruik, is er geen twijfel dat berichten met een geünificeerde markeerstift een goede kandidaat zijn voor onze implementatie.
Doorzoek de gegevens met Kibana
Als je de gegevens probeert te bevragen met Kibana, de dashboardsoftware voor datavisualisatie van Elasticsearch, zul je zien dat deze erg traag is. Het probleem komt niet van Elasticsearch, maar van de front-end applicatie van Kibana. Kibana probeert namelijk alle grote tekstvelden twee keer in de pagina te laden.
Ten eerste maakt het grote tekstveld deel uit van het bron_ veld. Om Kibana te versnellen, heb je geen andere keuze dan het grote tekstveld uit te sluiten van de bron. Je kunt dat doen in de indexpatroonconfiguratie onder het tabblad Veldfiltering_ in de nieuwere versie van Elasticsearch.
Ten tweede zal het gemarkeerde deel van het queryresultaat het volledige grote tekstveld bevatten in plaats van fragmenten. Een fragment is slechts een deel van de tekst dat de gemarkeerde waarde bevat. Laten we eens kijken naar het gemarkeerde deel van de gegenereerde query bij het uitvoeren van een zoekopdracht in het tabblad Zoeken:
"highlight": {
"pre_tags": [
"@kibana-highlighted-field@"
],
"post_tags": [
"@/kibana-highlighted-field@"
],
"fields": {
"*": {}
},
"fragment_size": 2147483647
}
De oorzaak van het probleem is de fragmentgrootte, die de maximale waarde van een geheel getal is. Kibana vraagt om het grootst mogelijke highlight fragment wat resulteert in het laden van het complete grote tekstveld. Kibana doet dit omdat we denken dat het op dit moment niet in staat is om meerdere highlighting fragmenten te tonen. Er is geen andere oplossing dan de highlighting-functie uit te schakelen in de geavanceerde instellingen van Kibana.
Conclusie
We hebben ontdekt dat Kibana niet werkt met grote tekstvelden, vooral niet voor de highlighting-functie. Als we een link willen leggen met het vorige artikel uit deel 1, dan is het zinvol om grote tekstvelden niet op te slaan om schijfruimte te besparen met een potentiële factor 2. We geloven sterk dat een speciale front-end applicatie nodig is om highlighting met grote tekstvelden voorlopig te implementeren in onze specifieke use cases.